
Criando um modelo 3D com IA
A evolução da inteligência artificial (IA) tem nos proporcionado ferramentas cada vez mais poderosas e acessíveis para a criação de conteúdo digital. Uma dessas ferramentas é o SHAP-E, uma biblioteca desenvolvida pela OpenAI que permite a geração de modelos 3D através de técnicas de difusão guiada por texto. Neste artigo, exploraremos como criar um modelo 3D de um tubarão usando o SHAP-E em um notebook do Colaboratory do Google Research. Já falamos sobre este assunto em nosso Podcast, usando o software Nething.XYZ, mas desta vez estamos falando principalmente de peças orgânicas!
Preparando o Ambiente
Clonando o Repositório SHAP-E
Observação: sempre que você encontrar “Código Python” deverá usar o código logo abaixo para executar no Notebook do seu Google Colaboratory.
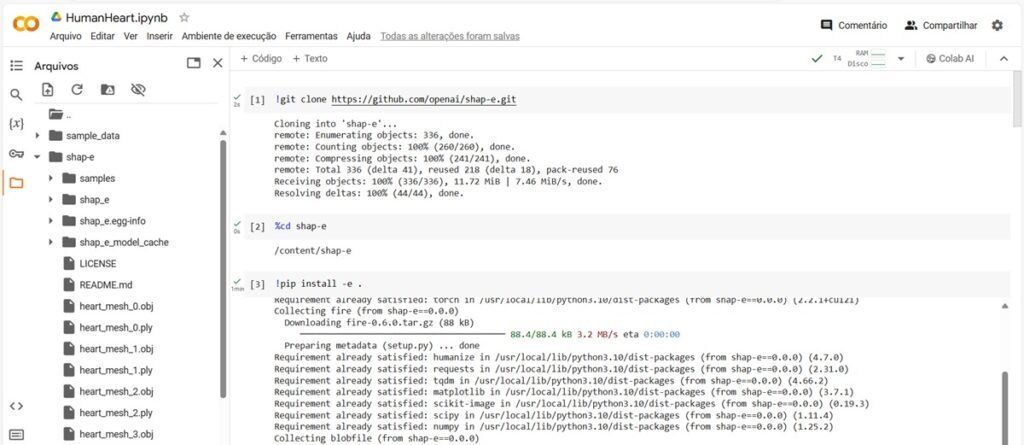
O primeiro passo para trabalhar com o SHAP-E é clonar seu repositório do GitHub no ambiente do Colab. Isso é feito com o seguinte comando:
Código Python
!git clone https://github.com/openai/shap-e.git
Este comando copia todo o código necessário para o nosso ambiente de trabalho na nuvem, permitindo-nos usar a biblioteca SHAP-E sem instalações locais.
Entrando no Diretório do Projeto
Após clonar o repositório, precisamos navegar para o diretório do SHAP-E dentro do nosso ambiente de trabalho:
Código Python
%cd shap-e
Este passo é crucial para garantir que todos os comandos subsequentes sejam executados no contexto correto.
Instalando Dependências
O SHAP-E tem várias dependências que precisam ser satisfeitas antes de podermos começar a trabalhar. Instalamos estas dependências executando:
Código Python
!pip install -e .
Este comando instala todas as dependências necessárias definidas no arquivo setup.py do SHAP-E, preparando nosso ambiente para a geração de modelos 3D.
Configurando o Ambiente de Execução
Importando Bibliotecas
Antes de começarmos a gerar modelos 3D, precisamos importar algumas bibliotecas essenciais do Python e do SHAP-E:
Código Python
import torch
from shap_e.diffusion.sample import sample_latents
from shap_e.diffusion.gaussian_diffusion import diffusion_from_config
from shap_e.models.download import load_model, load_config
from shap_e.util.notebooks import create_pan_cameras, decode_latent_images, gif_widget
Estas importações nos fornecem as funções necessárias para manipular modelos de difusão, carregar modelos pré-treinados e renderizar imagens.
Definindo o Dispositivo de Execução
Para aproveitar ao máximo a capacidade de processamento disponível, definimos o dispositivo de execução (CPU ou GPU) da seguinte maneira:
Código Python
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
Isso garante que nosso código seja executado na GPU, se disponível, acelerando significativamente o processo de geração de modelos 3D.
Gerando Modelos 3D
Carregando Modelos
Carregamos os modelos necessários para a geração de modelos 3D, especificamente o modelo de transmissão e o modelo de texto:
Código Python
xm = load_model('transmitter', device=device)
model = load_model('text300M', device=device)
diffusion = diffusion_from_config(load_config('diffusion'))
Estes modelos são fundamentais para interpretar nossos prompts de texto e gerar representações latentes que podem ser transformadas em modelos 3D.
Definindo Parâmetros de Geração
Antes de gerar os modelos 3D, definimos alguns parâmetros importantes, como o tamanho do lote, a escala de orientação e o prompt de texto (em inglês solicitamos a geração de um coração humano)
batch_size = 4 guidance_scale = 15.0 prompt = “human heart”
Estes parâmetros influenciam diretamente na qualidade e na diversidade dos modelos 3D gerados.
Gerando Latentes
Usamos a função sample_latents para gerar representações latentes a partir do nosso prompt de texto:
Código Python
batch_size = 4
guidance_scale = 15.0
prompt = "human heart"
latents = sample_latents(
batch_size=batch_size,
model=model,
diffusion=diffusion,
guidance_scale=guidance_scale,
model_kwargs=dict(texts=[prompt] * batch_size),
progress=True,
clip_denoised=True,
use_fp16=True,
use_karras=True,
karras_steps=64,
sigma_min=1e-3,
sigma_max=160,
s_churn=0,
)
Este processo utiliza técnicas avançadas de difusão para criar representações latentes que correspondem ao nosso prompt.
Renderizando Modelos 3D
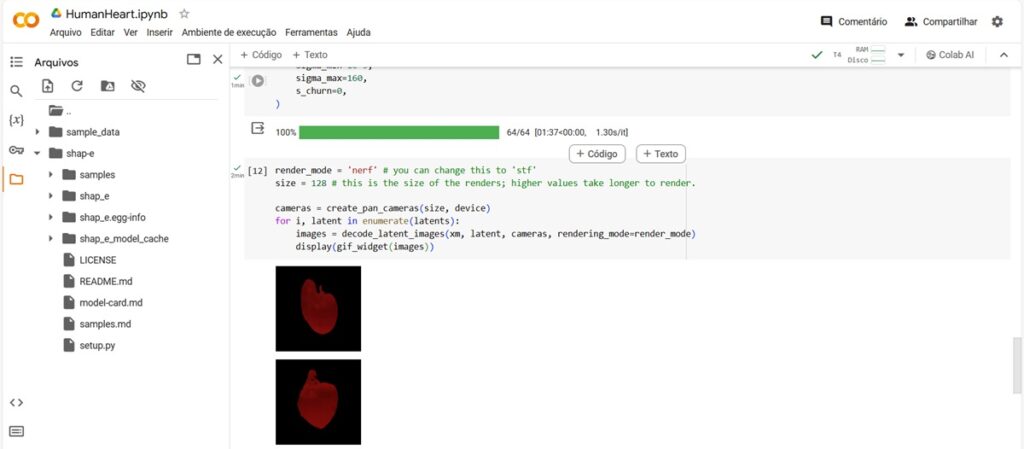
Após gerar as representações latentes, podemos renderizá-las em modelos 3D. Definimos o modo de renderização e o tamanho da renderização.
E, em seguida, usamos essas configurações junto com as câmeras panorâmicas para renderizar imagens dos modelos latentes:
Código Python
render_mode = 'nerf' # you can change this to 'stf'size = 128 # this is the size of the renders; higher values take longer to render.
cameras = create_pan_cameras(size, device)
for i, latent in enumerate(latents):
images = decode_latent_images(xm, latent, cameras, rendering_mode=render_mode)
display(gif_widget(images))
Salvando os Modelos como Malhas
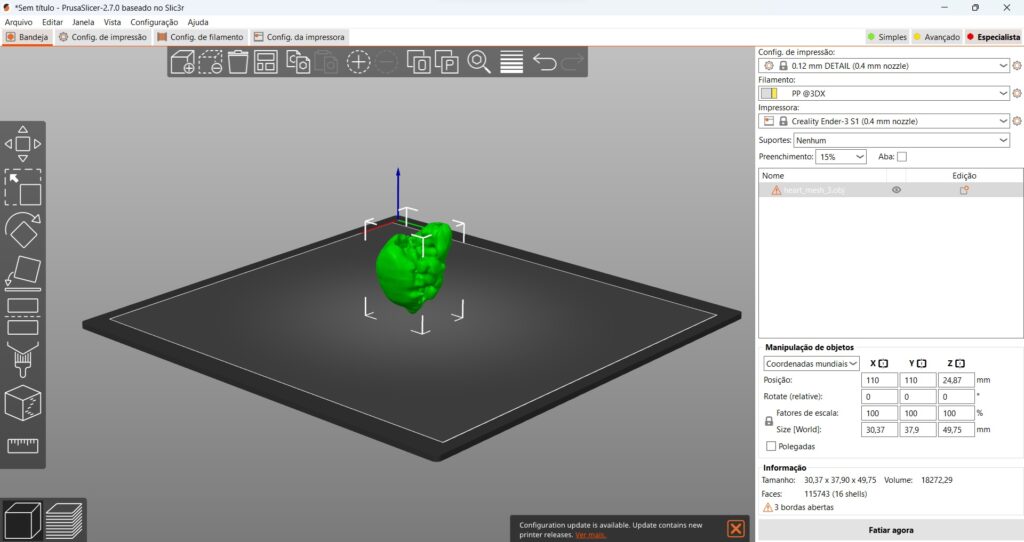
Por fim, oferecemos um exemplo de como salvar as representações latentes como malhas, que podem ser usadas em outros softwares de modelagem 3D:
pythonCopy code
from shap_e.util.notebooks import decode_latent_mesh
for i, latent in enumerate(latents):
t = decode_latent_mesh(xm, latent).tri_mesh()
with open(f'human_heart_mesh_{i}.ply', 'wb') as f:
t.write_ply(f)
with open(f'human_heart_mesh_{i}.obj', 'w') as f:
t.write_obj(f)
Este passo permite que os modelos 3D gerados sejam facilmente compartilhados e utilizados em diversas aplicações.
Conclusão
A capacidade de criar modelos 3D detalhados e realistas com base em prompts de texto abre novas possibilidades para artistas, designers e criadores de conteúdo. O SHAP-E, juntamente com as ferramentas de computação em nuvem como o Colaboratory do Google Research, torna esses avanços tecnológicos acessíveis a uma ampla gama de usuários, democratizando o acesso à última geração de ferramentas de IA.
Obrigado pela aula.
Na parte final do código o Colab. encontrou um erro e sugeriu uma modificação.
Não sou programador, logo não sei nem identificar o erro. De qualquer forma deixo a correção sugerida aqui abaixo:
>> Código corrigido
render_mode = ‘nerf’ # you can change this to ‘stf’
size = 128 # this is the size of the renders; higher values take longer to render.
cameras = create_pan_cameras(size, device)
for i, latent in enumerate(latents):
images = decode_latent_images(xm, latent, cameras, rendering_mode=render_mode)
display(gif_widget(images))
>>
Espero que ajude outras pessoas.
Até
Muito bom Tião! Conferindo e atualizando! Obrigado.